Constraint Semantic Parsing
SatIR uses LLM-based semantic parsers to independently translate free-text trial eligibility criteria and patient records into formal SMT constraint programs grounded in the SNOMED CT medical ontology.
Design principle. Clinical trial matching cannot, and need not, be fully captured in a formal language for retrieval. No finite symbolic language can express every clinical nuance. Instead of forcing all text into a rigid schema, SatIR designs a representation that is conservative and recall-oriented: it avoids excluding potentially eligible trials, while remaining as expressive as possible to filter out unsuitable ones.
SatIR represents clinical trials and patients as SMT formulas, canonicalizing terminology with the SNOMED CT medical ontology (350,000+ concepts, ~3 million relationships). Because SNOMED CT does not cover all concepts in patient records and trial text, SatIR extends it with non-canonical predicates whose semantics are specified by free-text descriptions, preserving fidelity to the source.
All information used for patient–trial matching must be represented explicitly. SatIR leverages SNOMED's subsumption structure for formal reasoning over canonicalized concepts. Missing patient data is handled via the salience assumption — see Constraint Augmentation.
Semantic parsing in SatIR is split into two independent pipelines: the trial-side parser (offline) translates eligibility criteria into SMT programs stored in the database; the patient-side parser (online) maps clinical notes into patient evidence that can be checked against trial formulas.
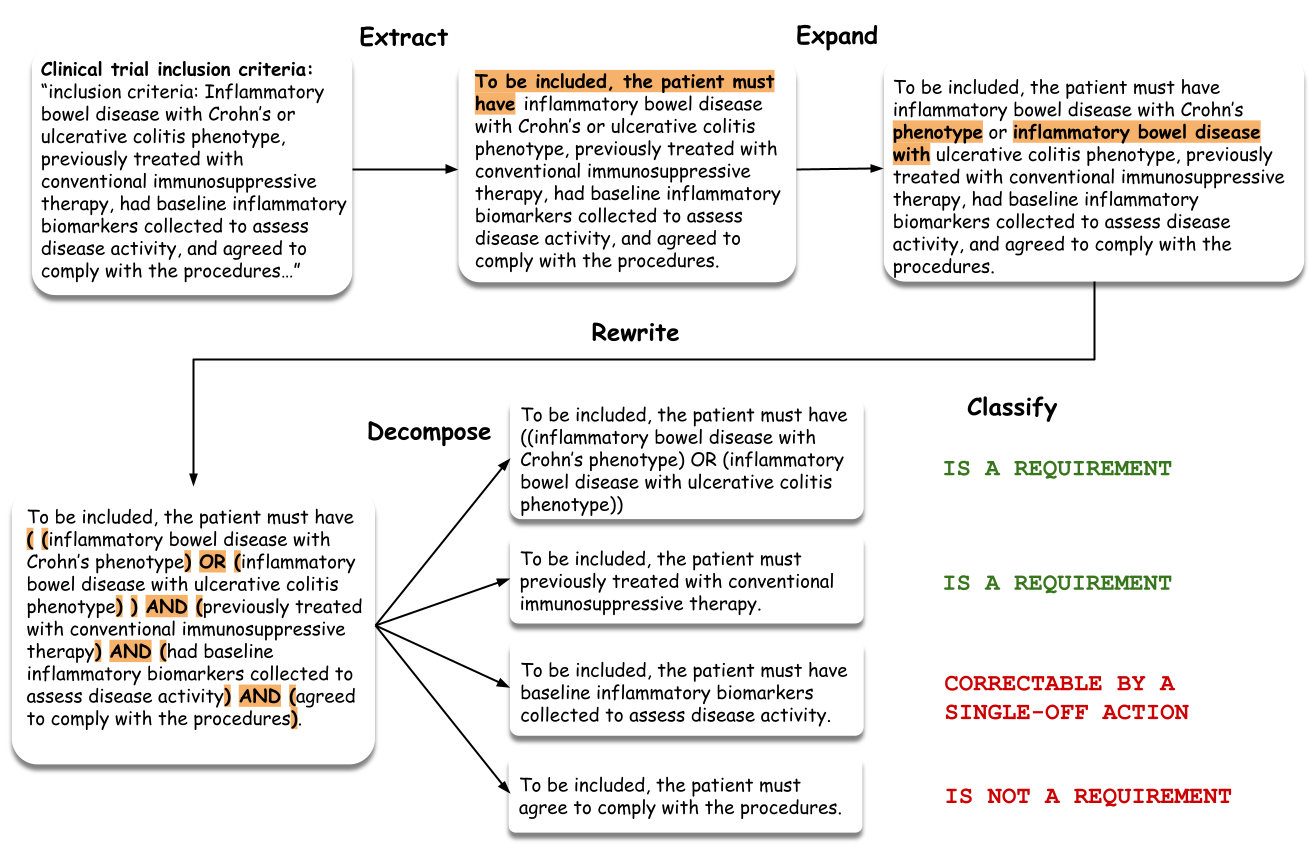
Raw eligibility criteria are difficult for end-to-end semantic parsing: a single trial mixes multiple enrollment pathways, medical entities appear in compressed or non-contiguous forms, logical structure is implicit, and individual sentences bundle several distinct constraints. Preprocessing addresses all of this before formalization by decomposing the problem into a sequence of simpler transformations, each removing one source of ambiguity.
Extract Requirements— §C.1.1
Organizes the trial into cohort-specific requirement lists, extracts requirement-bearing statements, and rewrites them into a standardized form with explicit polarity (inclusion/exclusion). This makes enrollment structure and cohort context explicit, which changes how individual criteria must be interpreted.
Expand Entities— §C.1.2
Rewrites each requirement so that medically meaningful mentions appear as explicit contiguous phrases — unpacking coordinated mentions, expanding abbreviated forms, and duplicating shared heads. The goal is not to add information but to expose entity structure already implicit in the criterion, making ontology grounding more reliable.
Rewrite Logic— §C.1.3
Surfaces implicit logical structure — conjunctions, disjunctions, modifier scope — so it can be interpreted deterministically. This step is meaning-preserving: it does not simplify the criterion but makes its latent compositional structure visible, reducing ambiguity in downstream parsing.
Decompose Requirements— §C.1.4
Splits rewritten requirements into smaller self-contained units — e.g., a sentence jointly constraining disease subtype, treatment history, and biomarker evidence becomes separate requirement statements. Each can then be canonicalized and translated independently, making failure localized and validation modular.
Classify— §C.1.5
Assigns each atomic requirement a prescreening role: (1) must be explicitly supported in patient notes, (2) not a real constraint or trivially satisfiable, or (3) may be unknown at prescreening but should not exclude a trial unless contradicted. This asymmetry is key — missing information should not prematurely eliminate potentially relevant trials unless the requirement is critical and expected to be known.
Faithfulness verification. SatIR applies lightweight verification checks between stages — verifying that polarity is preserved, content is not dropped, logical scope is not altered, and decomposition does not introduce semantic changes. When a check fails the system retries with targeted feedback; if unresolvable, it falls back to a less processed representation rather than risk semantic drift.
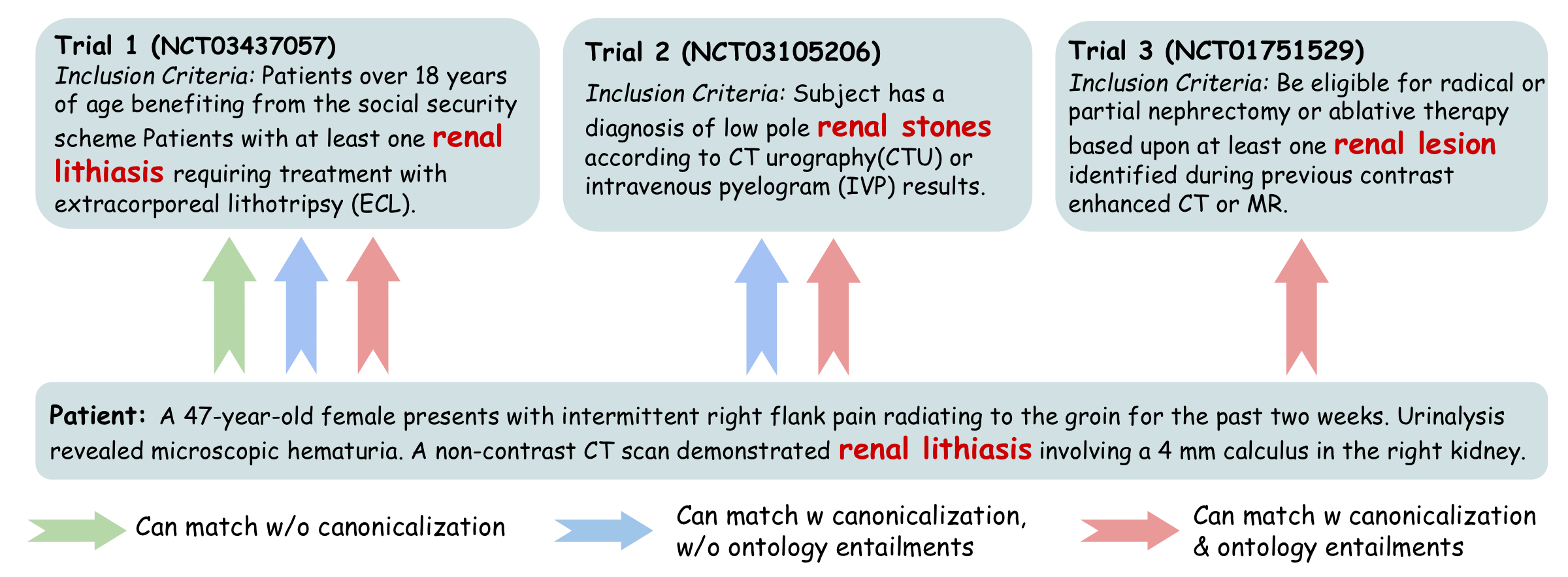
Clinical trials and patient records refer to the same underlying medical concept using different surface forms, abbreviations, levels of specificity, or paraphrases. A system operating on raw text spans therefore fails in two ways: it misses synonymy (semantically equivalent mentions do not match lexically), and it misses ontology-mediated generalization (a patient fact expressed at a more specific level should support a trial target at a more general level).
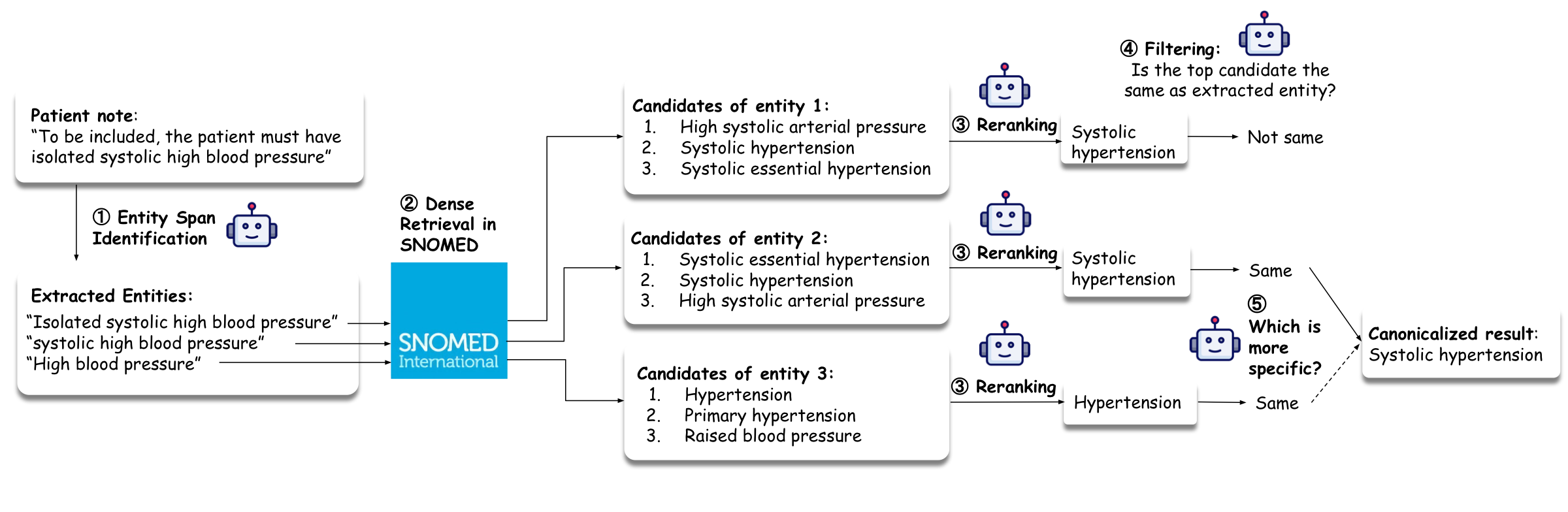
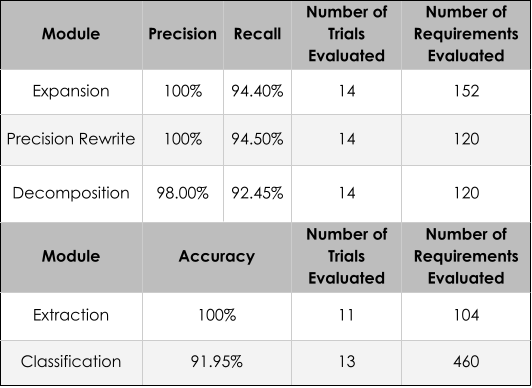
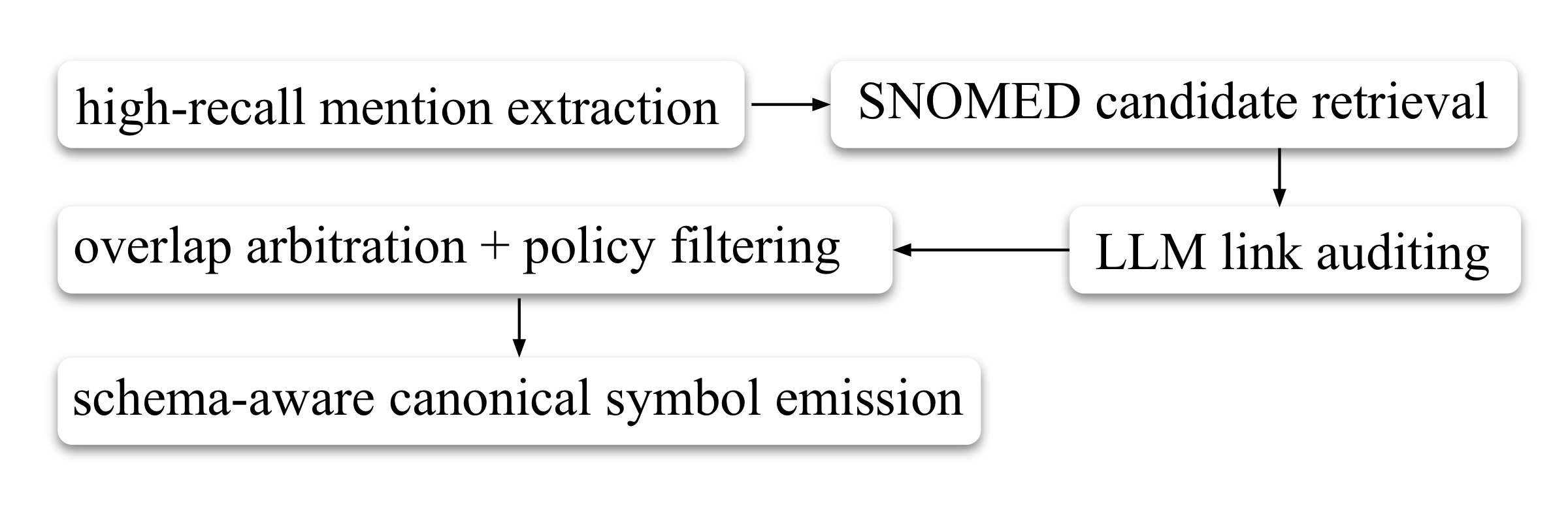
High-Recall Mention Extraction— §C.2.1
Identifies as many medically meaningful spans as possible, intentionally biased toward recall. Includes overlapping spans when they correspond to distinct plausible semantic units — an omitted mention cannot be recovered later and may directly cause false negatives.
Candidate Retrieval from SNOMED CT— §C.2.2
For each extracted span, retrieves top-k candidate concepts from SNOMED CT. Intentionally permissive — retains multiple plausible interpretations per span and defers disambiguation to later stages.
Contextual Link Auditing— §C.2.3
Accepts a candidate only if it is an exact meaning match in context — the candidate must neither lose clinically relevant semantics nor introduce unsupported semantics. A plausible but slightly incorrect link is often worse than leaving a mention uncanonicalized, since it introduces a false structured commitment.
Overlap Resolution & Policy Filtering— §C.2.4
Handles overlapping spans that survived earlier stages. Enforces representation constraints required by the downstream reasoning system, discards unsupported concept types, and among overlapping candidates keeps the most specific acceptable concept.
Schema-Aware Canonical Symbol Emission— §C.2.5
Converts each accepted concept into a schema-aware canonical symbol encoding both the grounded medical concept and its semantic role (diagnosis, finding, procedure, medication, measurable observable). This shared symbol is reused consistently across patient parsing, trial parsing, database storage, retrieval, and formal reasoning.
Even after structured decomposition and entity canonicalization, direct one-shot translation from free-text eligibility criteria to a full SMT program is brittle — variables are redeclared inconsistently, qualifiers are dropped or attached to the wrong concept, polarity is inverted, and the resulting program may be syntactically valid but semantically unsupported. SatIR therefore uses an incremental orchestration procedure in which requirements are translated one at a time, validated immediately, and committed only when judged reliable.
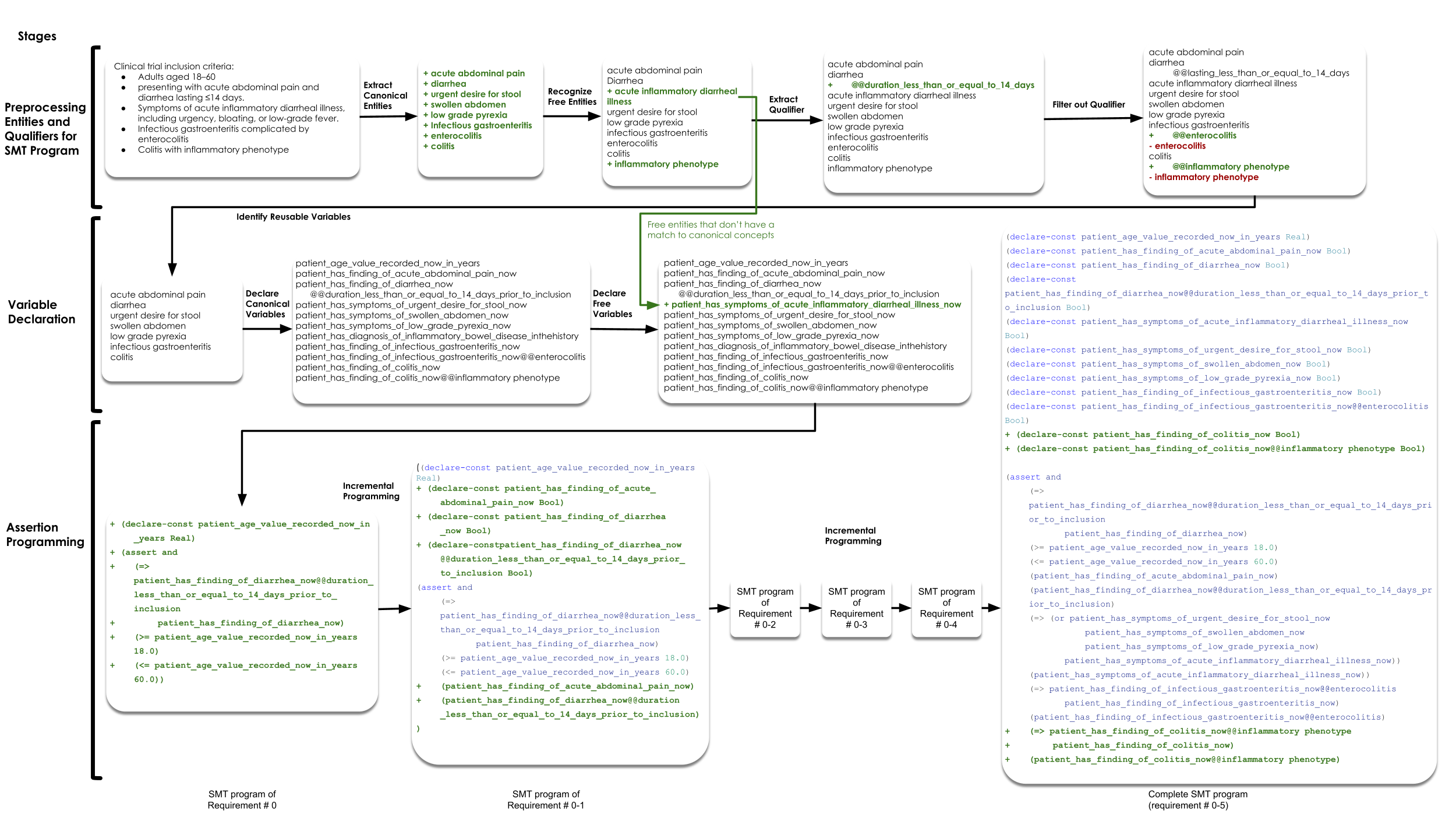

The incremental driver separates five subproblems per requirement: (1) identifying previously declared symbols to reuse, (2) resolving qualifier–entity attachment, (3) constructing new variables when necessary, (4) translating to a local SMT fragment, and (5) validating that fragment logically and semantically before committing. This decomposition makes the overall synthesis more stable and more auditable than monolithic generation.
After initial SMT programming, SatIR applies a post-processing repair pipeline to improve trial-side programs. The goal is not to re-parse from scratch, but to repair and tighten existing SMT programs so they more faithfully encode the intended eligibility logic while preserving a conservative retrieval policy. The pipeline applies a sequence of specialized LLM-based repair stages:
repair → polarity → logic → gate → underconstraint → meaning
Each stage overwrites the canonical SMT file in place when a valid repair is produced, and records a complete before/after snapshot with debugging artifacts. Early stages correct semantic drift (polarity, malformed logic); later stages remove files with no real criteria, tighten underconstrained encodings, and ensure every variable has a self-contained machine-readable definition. (Appendix §C.4)
The patient-side pipeline maps raw clinical notes into the same ontology-backed symbolic vocabulary used on the trial side. The key distinction: the trial-side parser compiles a full eligibility formula (compositional requirements); the patient-side parser recovers atomic SMT-grounded assertions (evidence about one individual) that downstream evaluation checks against the formula.
The pipeline is designed around four requirements: (1) clinical faithfulness — separating explicit statements from plausible but uncertain inferences, requiring every extracted fact to be justified by evidence; (2) direct symbolic executability — outputs must be normalized into ontology-grounded atomic forms renderable as Boolean predicates, numeric assignments, and temporalized SMT-ready evidence; (3) fine-grained auditability — each stage emits an interpretable artifact so failures can be localized; (4) conservatism under uncertainty — preferring explicit support and preserving uncertainty rather than overcommitting. (Appendix §C.7)
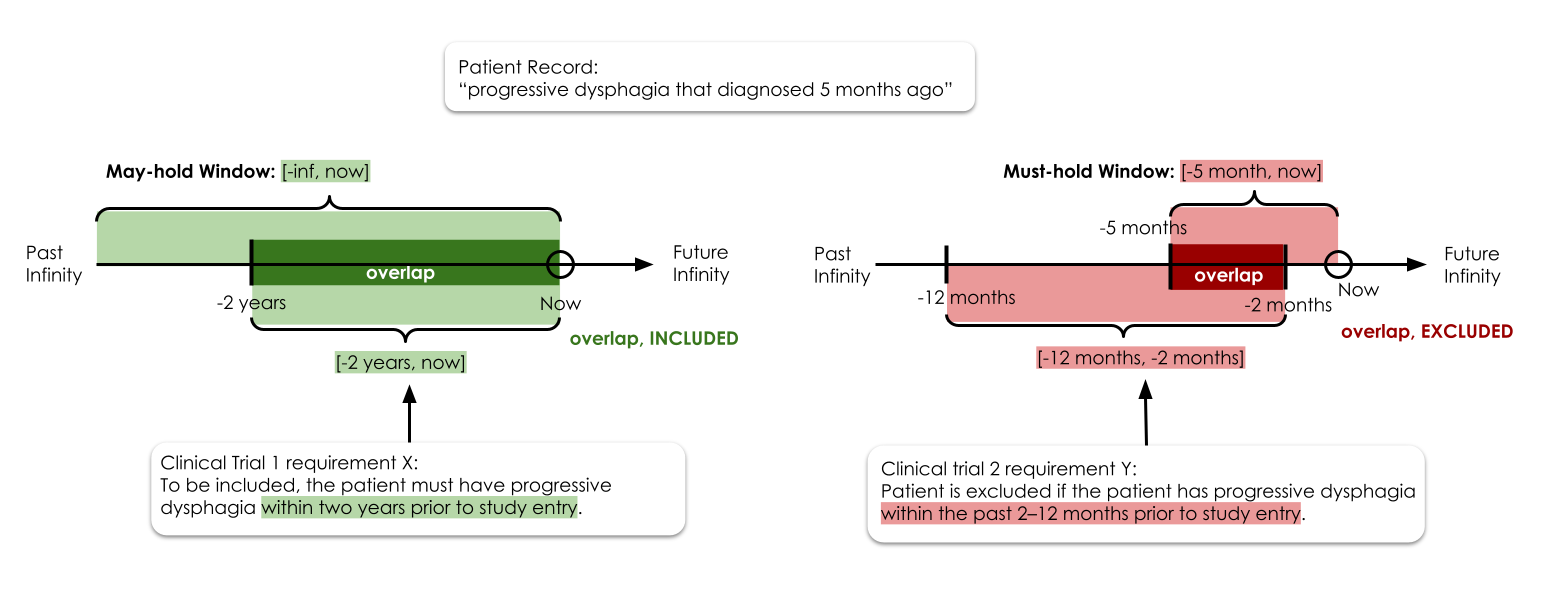
Temporal expressions in patient notes are converted into explicit, conservative time windows for eligibility evaluation. Each extracted patient fact is assigned two intervals: a may-hold window (the time interval during which the patient may have the condition) and a must-hold window (the interval during which they definitely do). For inclusion criteria, overlap with the may-hold window indicates eligibility; for exclusion criteria, overlap with the must-hold window indicates ineligibility. This asymmetry ensures conservative, recall-safe evaluation.